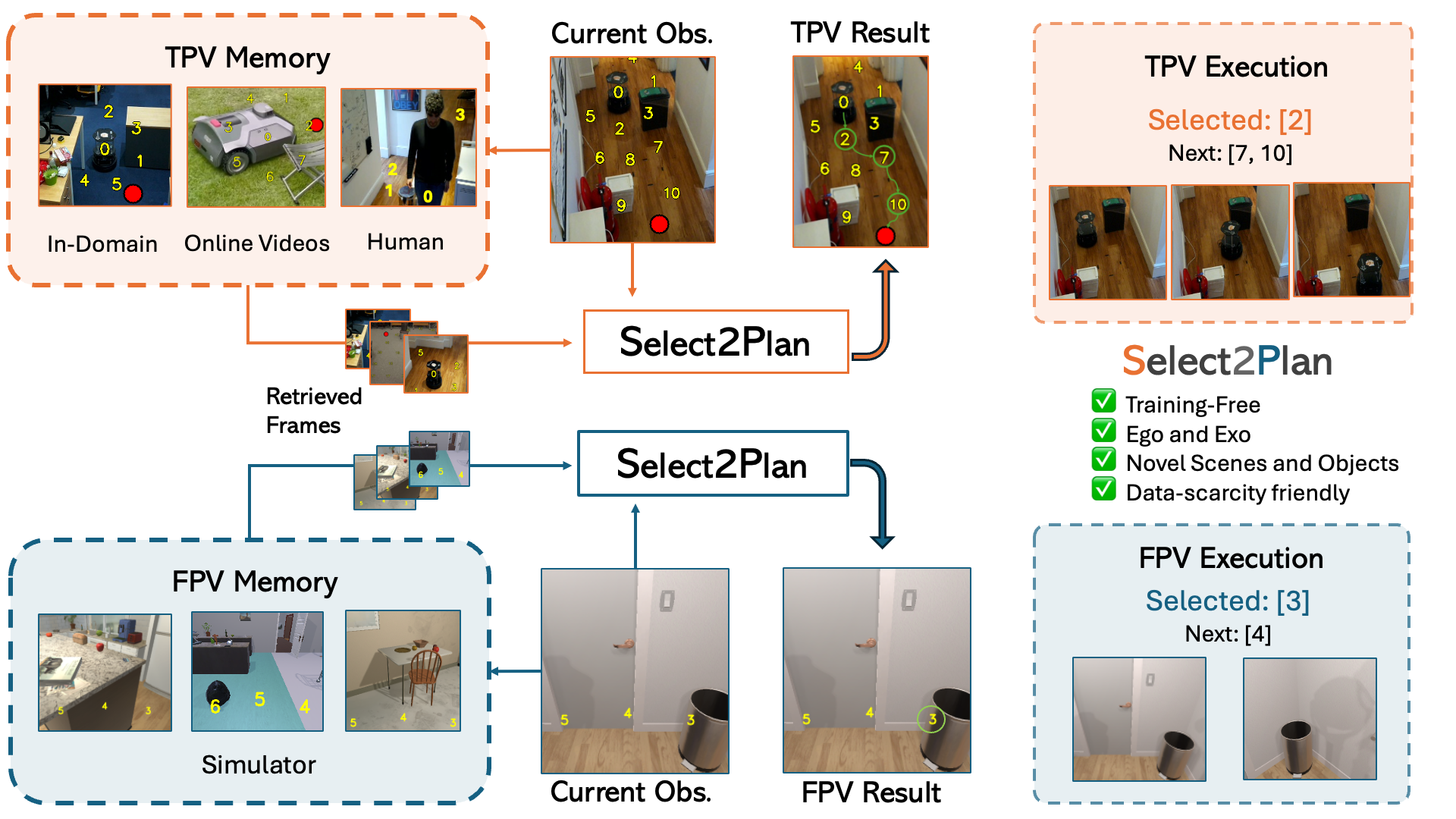
We introduce Select2Plan (S2P), a novel training-free framework for high-level robot planning that leverages off-the-shelf VLMs for autonomous navigation. Unlike most learning-based approaches that require extensive task-specific training and large-scale data collection, S2P overcomes the need for fine-tuning by adapting inputs to align with the VLM's pretraining data. Our method achieves this through a combination of structured Visual Question Answering (VQA) to ground action selection on the image, and In-Context Learning (ICL) to exploit knowledge drawn from relevant examples from a memory bank of (visually) annotated data, which can include diverse, in-the-wild sources. We demonstrate S2P flexibility by evaluating it in both First-Person View (FPV) and Third-Person View (TPV) navigation. S2P improves the performance of a baseline VLM by 40% in TPV and surpasses end-to-end trained models by approximately 24% in FPV when tasked with navigating towards unseen objects in novel scenes. These results highlight the adaptability, simplicity, and effectiveness of our training-free approach, demonstrating that the use of pre-trained VLMs with structured memory retrieval enables robust high-level robot planning without costly task-specific training. Our experiments also show that retrieving samples from heterogeneous data sources, including online videos of different robots or humans walking, is highly beneficial for navigation. Notably, our method effectively generalizes to novel scenarios, requiring only a handful of demonstrations.
Select2Plan (S2P) is a novel framework for high-level robot navigation that eliminates the need for extensive training or fine-tuning. In order to to that, the system leverages off-the-shelf Vision-Language Models (VLMs) combined with Visual Question-Answering (VQA) to make decisions without the need for specialized data collection. The secret is riformulating the problem in a way that is compatible with the VLM's pretraining data.
S2P adapts effortlessy to different navigation scenarios, including First-Person View (FPV) and Third-Person View (TPV). This versatility enables it to operate in various conditions, from autonomous vehicle pathfinding to CCTV-based robotic control.
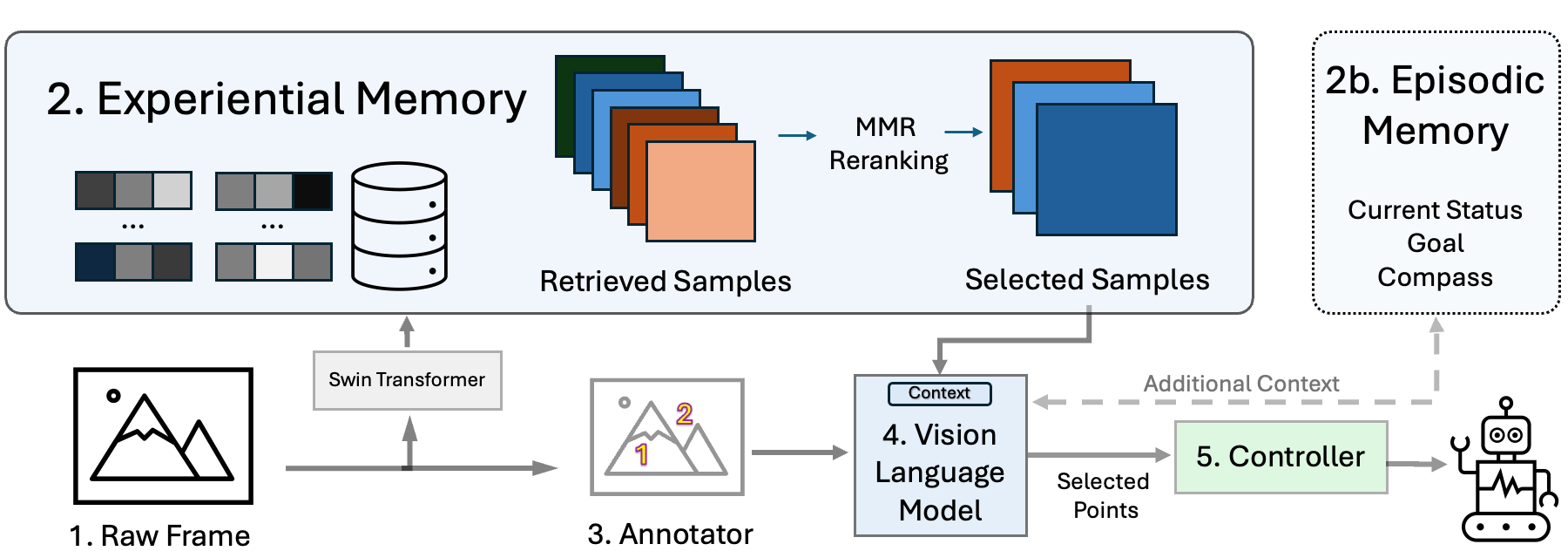
S2P incorporates In-Context Learning (ICL) combined with experiential memory to generate robust plans.
The memory retrieval system enables the robot to learn from previous experiences and generalize to new, unseen environments, improving navigation performance by as much as 50% without the need for additional training. S2P even outperforms heavily trained models in FPV setup, achieving impressive results (+24%) with significantly fewer data, making it an efficient solution for high-level robot planning and navigation. Record some demos and you are ready to go!
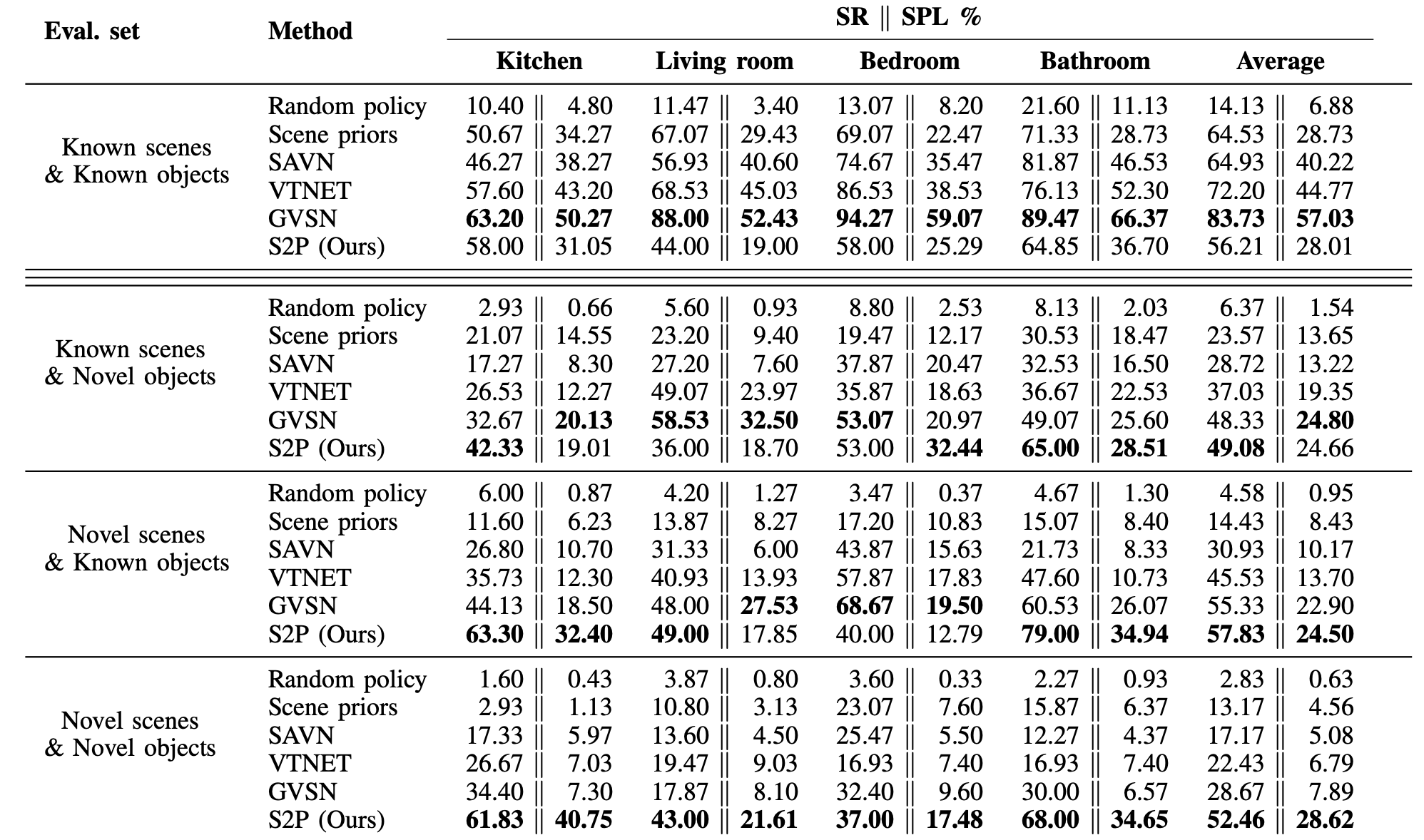
In the FPV setup, our model, referred to as Select2Plan (S2P), was evaluated against state-of-the-art methods in a variety of scenarios. The average Success Rate (SR) of 46.16% in known scenes with known objects reflects the model's ability to perform well even with a minimal training dataset. Compared to the best-performing model, which was trained on 8 million episodes, S2P required only a fraction of the data, specifically one episode per object type (total of 15). Despite this, S2P managed to achieve great improvements (up to +24%), highlighting the efficiency of our approach in leveraging pre-trained Vision-Language Models (VLMs) for efficient knowledge transfer.
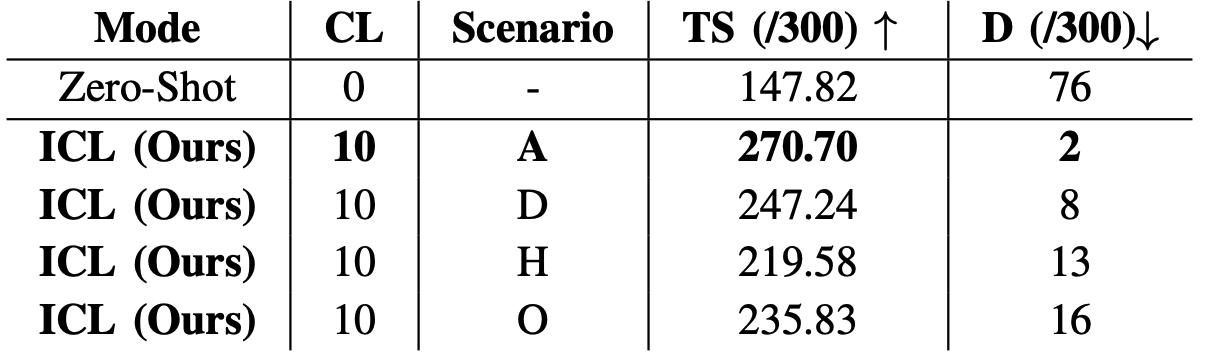
We also investigate how different data sources can affect the performance of S2P. In TPV scenario, we evaluate the performance of context coming from three different sources: same deployment scenario and same rooms, same scenario, different rooms same scenario, humans as demonstrators and finally, different scenario and different robotic support (online data).

Our In-Context Learning (ICL) approach demonstrated significant improvements in the TPV scenario. The highest Trajectory Score (TS) achieved was 270.70 in context scenario A, which allows unrestricted retrieval from the database, compared to the baseline zero-shot approach, which scored 147.82. This represents a over 40% improvement, indicating that our model can effectively leverage contextual information to enhance navigational accuracy and safety. In addition to the overall TS improvement, the framework showed a remarkable 38% reduction in selecting dangerous points (DS), which indicates locations with a high risk of collision. This reduction is crucial for real-world applications, where safety and reliable navigation are paramount. Such performance gains were consistent across different context scenarios, further highlighting the versatility and adaptability of the proposed approach. What is really interesting is the ability to generalize cross embodiement using as instance demos of other robots or humans walking.
@ARTICLE{11151762,
author={Buoso, Davide and Robinson, Luke and Averta, Giuseppe and Torr, Philip and Franzmeyer, Tim and Martini, Daniele De},
journal={IEEE Robotics and Automation Letters},
title={Select2Plan: Training-Free ICL-Based Planning Through VQA and Memory Retrieval},
year={2025},
volume={10},
number={11},
pages={11267-11274},
keywords={Navigation;Robots;Planning;Visualization;Cameras;Training;Adaptation models;Transformers;Predictive models;Oral communication;Motion and path planning;vision-based navigation;autonomous agents},
doi={10.1109/LRA.2025.3606790}}