publications
ordered by date
2026
-
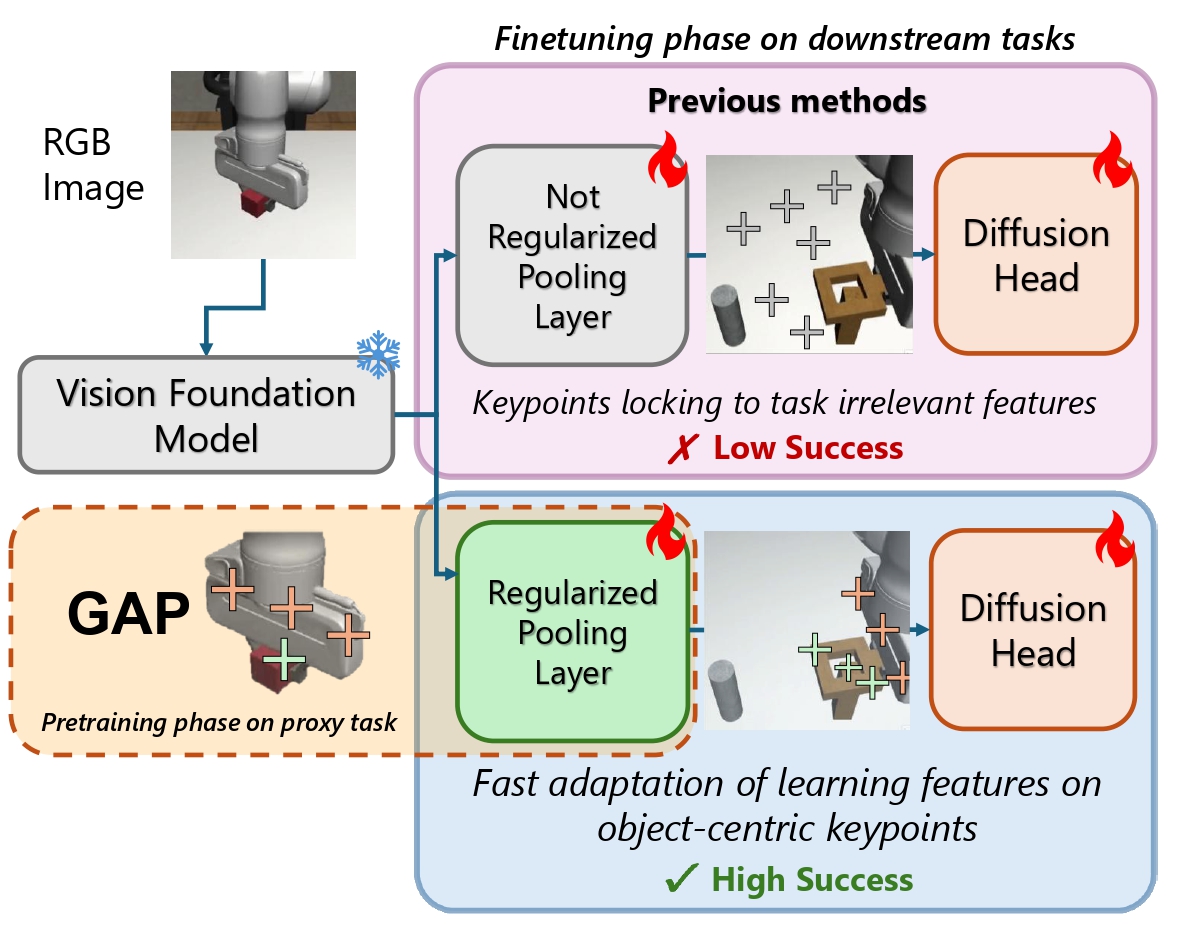 GAP: Geometric Anchor Pre-training for Data-Efficient Visuomotor Learning of Manipulation TasksDavide Buoso, Andrea Protopapa, Stefano Di Carlo, Francesca Pistilli and Giuseppe AvertaUnder Review, 2026
GAP: Geometric Anchor Pre-training for Data-Efficient Visuomotor Learning of Manipulation TasksDavide Buoso, Andrea Protopapa, Stefano Di Carlo, Francesca Pistilli and Giuseppe AvertaUnder Review, 2026Learning visuomotor policies from scarce expert demonstrations remains a core challenge in robotic manipulation. A primary hurdle lies in distilling high-dimensional RGB representations into control-relevant geometry without overfitting. While using frozen pretrained Vision Foundation Models (VFMs) improves data efficiency, it also shifts most task adaptation onto a small spatial pooling module, which can latch onto task-irrelevant shortcuts and lose geometric grounding when finetuned with few data samples. More broadly, pretrained visual representations used for policy learning have been observed to struggle under even minor scene perturbations, highlighting the need for robustness-oriented inductive biases. We propose Geometric Anchor Pre-training (GAP), a simple, action-free warm-up stage that regularizes the spatial adapter before downstream imitation learning. GAP pre-trains the pooling layer on a lightweight simulated proxy task where object masks are available at no cost, encouraging the adapter to produce keypoints that lie on the object, cover its spatial extent (instead of collapsing), and remain sharp and repeatable over time. This yields stable geometric anchors that provide a reliable coordinate interface for few-shot policy learning, while keeping the VFM frozen. We evaluate GAP on RoboMimic and ManiSkill under severe data scarcity (15-50 demonstrations) and domain shift. A simple adapter regularized with GAP consistently outperforms stronger attention-based poolers and end-to-end fine-tuning, achieving 62% success on RoboMimic Can with 15 demonstrations (+16% over AFA), 63% on the long-horizon high-precision Tool Hang task with 50 demonstrations (+13% over the best competitor based on R3M with Spatial Softmax), and 61% on ManiSkill StackCube with 30 demonstrations (+11% over full fine-tuning). The proxy stage is lightweight (about 40 minutes on a single consumer GPU) and fully decoupled from downstream tasks, making it practical to reuse across environments and manipulation skills.

2025
-
 Select2Plan: Training-Free ICL-Based Planning through VQA and Memory RetrievalDavide Buoso, Luke Robinson, Giuseppe Averta, Philip Torr, Tim Franzmeyer and Daniele De MartiniIEEE Robotics and Automation Letters (RA-L), 2025
Select2Plan: Training-Free ICL-Based Planning through VQA and Memory RetrievalDavide Buoso, Luke Robinson, Giuseppe Averta, Philip Torr, Tim Franzmeyer and Daniele De MartiniIEEE Robotics and Automation Letters (RA-L), 2025This study explores the potential of off-the-shelf Vision-Language Models (VLMs) for high-level robot planning in the context of autonomous navigation. Indeed, while most of existing learning-based approaches for path planning require extensive task-specific training/fine-tuning, we demonstrate how such training can be avoided for most practical cases. To do this, we introduce Select2Plan (S2P), a novel training-free frame work for high-level robot planning which completely eliminates the need for fine-tuning or specialised training. By leveraging structured Visual Question-Answering (VQA) and In-Context Learning (ICL), our approach drastically reduces the need for data collection, requiring a fraction of the task-specific data typically used by trained models, or even relying only on online data. Our method facilitates the effective use of a generally trained VLM in a flexible and cost-efficient way, and does not require additional sensing except for a simple monocular camera. We demonstrate its adaptability across various scene types, context sources, and sensing setups. We evaluate our approach in two distinct scenarios: traditional First-Person View (FPV) and infrastructure-driven Third-Person View (TPV) navigation, demonstrating the flexibility and simplicity of our method. Our technique significantly enhances the navigational capabilities of a baseline VLM of approximately 50% in TPV scenario, and is comparable to trained models in the FPV one, with as few as 20 demonstrations.

2024
-
 Enhanced Localization of ArUco Markers for Autonomous Robotics: A Comparative StudyAlessandro Minervini, Davide Buoso, Jean Carlos Quito Casas, Davide Fassio, Claudio Giuseppe Messina, Francesco Marino and Giorgio GuglieriEuropean Robotics Forum (ERF), 2024
Enhanced Localization of ArUco Markers for Autonomous Robotics: A Comparative StudyAlessandro Minervini, Davide Buoso, Jean Carlos Quito Casas, Davide Fassio, Claudio Giuseppe Messina, Francesco Marino and Giorgio GuglieriEuropean Robotics Forum (ERF), 2024Autonomous drone technology increasingly enables their use in diverse applications, offering cost and time benefits in precision agriculture and surveillance. They are especially efficient in search and rescue and exploring hard-to-access areas. Navigating indoor settings and partially known environments poses significant challenges in autonomous robotics. This paper introduces a novel method that leverages depth image data to substantially improve performance in these contexts. We elucidate the method’s design, showcasing its dependability and advantages over conventional approaches. Furthermore, the paper delineates the critical procedures for effective autonomous robot guidance, tackling complex obstacles inherent to the field.
-
 SpanLuke: Enhancing Legal NER using SpanMarker and LoRA (NP)Davide Buoso, Enrico Capuano, Andrea Caselli and Destiny OkpekpeStudent Project, 2024
SpanLuke: Enhancing Legal NER using SpanMarker and LoRA (NP)Davide Buoso, Enrico Capuano, Andrea Caselli and Destiny OkpekpeStudent Project, 2024Legal Named Entity Recognition is a focal point in NLP systems in legal domain, due to its potential to streamline processes and enhance decision-making accuracy. This paper delves into the SpanMarker technique for span-level representation of entity, the LUKE model for enhanced entity recognition and LoRA for efficient fine-tuning of large models. The study evaluates these methodologies, individually and in synergy, to improve the accuracy and performance of legal NLP systems. Additionally, a new dataset (EDGAR-NER) has been explored. In-depth experimentation reveals the potential of these approaches. This research contributes to ongoing efforts in leveraging NLP to enhance legal text process, reducing the time needed to train models to achieve this goal.

2023
-
 Exploring Federated Learning for Semantic Segmentation in Autonomous Driving and Satellite Images Scenarios (NP)Davide Buoso, Marco Castiglia and Giacomo ZulianiStudent Project, 2023
Exploring Federated Learning for Semantic Segmentation in Autonomous Driving and Satellite Images Scenarios (NP)Davide Buoso, Marco Castiglia and Giacomo ZulianiStudent Project, 2023This project explores the application of Federated Learning (FL) to the task of Semantic Segmentation (SS), with a focus on preserving client privacy while utilizing their data for model training. The proposed approach involves a centralized server pre-training phase on a labeled dataset, incorporating a style-transfer technique for domain adaptation. In the federated decentralized setting, our approach tackles the challenge of absent labels on client data. By leveraging pseudo-labels and self-training, the approach enables the utilization of unlabeled client images, effectively addressing the issue of limited ground truth availability. The report also provides additional insights into extending the applicability of this approach to domains beyond self-driving cars, such as satellite imagery. Additionally, an intriguing possibility explored in this project is the integration of a transformer model into the existing framework, presenting a promising alternative to the commonly employed CNN architectures.
